I’m now using Enlive to create the HTML for the report. Enlive offers very strong separation between business code and HTML. Since the Enlive template is just a normal HTML file, I can edit it using impatient-mode and see the impact of my work immediately.
Here’s a video of me using impatient-mode to sequentially enable chunks of CSS while seeing the browser update instantly.
I’ve made significant performance improvements to impatient-mode since I recorded this initial demo. Here is an example of refreshing the CSS on the Clojurescript benchmark site. And this demonstrates live editing with 3 browsers at the same time.
My frequent co-conspirator, Chris Wellons, created a HTTP server that runs entirely within Emacs. He made some updates recently that inspired me to create impatient-mode.
impatient-mode uses Chris’s HTTP Server to serve the Emacs buffer of your choice. impatient-mode serves up this buffer along with a thin shim page that makes the browser automatically refresh itself from your buffer as you type.
Chapter 2 of Prolog Programming For Artificial Intelligence introduces a classic AI problem involving a monkey and a banana.
A monkey is in a room that contains a banana and a box. The banana is in the middle of the room and is out of the monkey’s reach if the monkey is standing on the floor. But, if the monkey positions the box properly and stands on it then the monkey will be able to reach the banana. The monkey is allowed to walk around the room, push the box, climb the box, and reach for the banana. They question is, given a particular starting room configuration, can the monkey reach the banana?
The state of monkey-world can be expressed as a 4-tuple. The terms that make it up are:
Where the monkey is in the room
If the monkey is on the box
Where the box is in the room
If the monkey has the banana
In Prolog, we express this using a named structure with 4 parameters. For example:
1
state(middle,onbox,middle,hasnot)
In this configuration, the monkey is in the middle of the room and is standing on the box (also in the middle of the room) and it does not have the banana.
In Core.Logic, we don’t really have a concept that maps directly to Prolog’s named structures but we do have full access to Clojure’s rich data-types. A simple array will do what we need. We could tag the array with a name but that information isn’t needed for this example. We’ll just express the state of the world as an unnamed 4-vector of symbols:
1
[:middle:onbox:middle:hasnot]
The monkey can interact with the world by:
Grabbing the banana
Climbing the box
Pushing the box
Walking around the room
Not all actions are always possible. The available actions depend on the state of the world and applying an action to a world-state produces a new world-state.
In Prolog, we can encode the “grabbing the banana” action as a relation between the initial world-state, the action, and the resulting world-state:
In English: If the monkey is in the middle of the room and on the box (also in the middle of the room) and it doesn’t have the banana and it uses the grasp action then it will have the banana.
This relation introduces the idea of unbound positions in a relation. In Prolog, if a slot in a relation is filled in with a symbol that begins with capital letter then that slot is unbound. Prolog can often apply rules to figure out what the unbound slots in a relationship should be bound to. If the same capitalized symbol fills multiple slots in a relation then those slots should be bound to the same value once Prolog discovers what the value is.
The monkey can push the box from one position to another if the monkey and the box are in the same place. Once the monkey is done pushing then the monkey and the box will be in the new place.
This is like box pushing but only the monkey’s position changes in the new world-state.
That’s quite enough Prolog for the moment. It’s time to introduce a new Core.Logic macro: The Mighty “defne” (which I like to pronounce “Daphne”.)
A defne Interlude
defne combines conde style rules with some powerful sugar that saves us from having to explicitly introduce some of our variables with fresh. It’s difficult to grasp until you’ve used it so let’s try getting there through a few examples.
In the my previous post I defined a relation called parent and added facts to that relation. Here’s that again but with defne:
The macro-expansion sheds some light on what’s going on here:
1234567891011121314
(macroexpand '(defneparent....));; approximately expands to(defn parent[elderchild](conde((== :pamelder)(== :bobchild))((== :tomelder)(== :bobchild));; and so on...))
We’re defining a new function of two variables. This new function uses conde to provide a series of possible relations. Remember, conde is somewhat like a logical OR. Within each option, defne has bound (actually, unified) each slot of the vector with the corresponding slot in the arguments to the function.
defne isn’t very exciting when you put only constants in the binding slots. Let’s introduce some variables also:
This has expanded to a conde with two cases. The first case applies when X is the empty list. This case also unifies its result variable Z with Y. In English, the result of appending the empty list X onto Y is the same as just Y.
The next case has introduced some new variables using fresh. These correspond to the variables we used in the first part of the second case. Here we’re unpacking X into its head A and its tail D. We’re also packing something new into our result variable Z and we’re recursively calling ourselves. In English, the result of appending the non-empty list X onto Y is the result of appending the tail of X onto Y and then sticking the head of X in front of that.
appendo is tricky. The big idea to grasp for this post is that defne pattern matches against its input variables and is useful for unpacking things like lists and doing interesting things with their contents.
Solution to Monkey and Banana
Using defne we can encode our monkey movement rules in even less space than Prolog required:
Core.Logic answers that the monkey can climb, push the box from the middle to somewhere, or walk from the middle to somewhere. Grasping the banana isn’t possible from this position.
Now that we’ve encoded how moves affect the world-state we just need to find out if there is a sequence of moves that will let the monkey reach its goal. Can the monkey get the banana?
Ivan Bratko makes the point that the Prolog version of this program is sensitive to the order of its rules. If you re-arrange the final two expressions in canget then the resulting program will never find a solution:
This is because Prolog does a depth-first search of its solution space. The Prolog version of this program gets stuck recursing into the next call to canget before it ever constrains State2 by applying a new Move.
Happily, Core.Logic isn’t sensitive in this way and will execute its similarly altered program to the correct conclusion:
Chapter 1 of Ivan Bratko’s book introduces an example logic program that reasons about relationships in a family.
The program starts out by defining some facts:
12345678910111213141516
/* pam is bob's parent, and so on... */parent(pam,bob)parent(tom,bob)parent(tom,liz)parent(bob,ann)parent(bob,pat)parent(pat,jim)/* pam is female... */female(pam)male(tom)male(bob)female(liz)female(ann)female(pat)male(jim)
We can translate this into Clojure Core.Logic fairly directly:
123456789101112131415161718192021
;; define the relations and their arity(defrelparentpc)(defrelmalep)(defrelfemalep);; add facts to the relations. Again, :pam is :bob's parent(factparent:pam:bob)(factparent:tom:bob)(factparent:tom:liz)(factparent:bob:ann)(factparent:bob:pat)(factparent:pat:jim);; and :pam is female(factfemale:pam)(factmale:tom)(factmale:bob)(factfemale:liz)(factfemale:ann)(factfemale:pat)(factmale:jim)
At this point we can ask the program to recite the facts back to us. For example, who are Bob’s parents?
In prolog:
1
?-parent(X,bob)
and prolog answers:
12
X=tomX=pam
In Clojure’s Core.Logic:
12
(run*[q](parentq:bob))
and Core.logic answers:
1
(:tom:pam)
Things get more interesting when we start adding rules to the program so that the system can start deriving new facts. For example, we can add a rule describing what a mother is:
In prolog:
123
mother(X,Y):-parent(X,Y),female(X)
This reads: “X is the mother of Y if X is the parent of Y and X is female.”
In Core.logic:
1234
(defn mother[xy](fresh[](parentxy)(femalex)))
Now we can ask who Bob’s mother is:
12345
(run*[q](motherq:bob));; answer(:pam)
Or, we can move the variable and ask we has Pam as a mother:
12345
(run*[q](mother:pamq));; answer(:bob)
I’ll provide the rest of the Core.logic version of the family program without much explanation. The important things you need to know to understand this code are:
run* executes a logic program for all of its solutions
fresh creates new lexically scoped, unbound variables. All clauses inside fresh are logically AND’d together
conde similar to an OR. Each conde clause is asserted independently of the others.
;; C is the offspring of P if P is the parent of C(defn offspring[cp](parentpc));; X is the grandparent of Z if, for some Y, X is the parent;; of Y and Y is the parent of Z(defn grandparent[xz](fresh[y](parentxy)(parentyz)));; X is the grandmother of Y if X is the grandparent of Y and;; X is a female(defn grandmother[xy](fresh[](grandparentxy)(femalex)));; X is the sister of Y if, for some Z, Z is the parent of X;; and that same Z is the parent of Y and X is female and;; Y and X are not the same person.(defn sister[xy](fresh[z](parentzx)(parentzy)(femalex)(!=xy)));; X is a predecessor of Z if X is the parent of Z or if;; X is the parent of some Y and that Y is a predecessor;; of Z(defn predecessor[xz](conde[(parentxz)][(fresh[y](parentxy)(predecessoryz))]))
The final rule is especially interesting because it introduces logical recursion. Notice that predecessor is defined in terms of itself.
Now some examples of what this program can derive:
Those who have worked with me know that I can become a bit obsessed with optimizing software. I like to think that as I’ve matured as a developer I’ve become more strategic and disciplined in my optimizations. Regardless, when programming, I’m often at my happiest when I’m making code go faster.
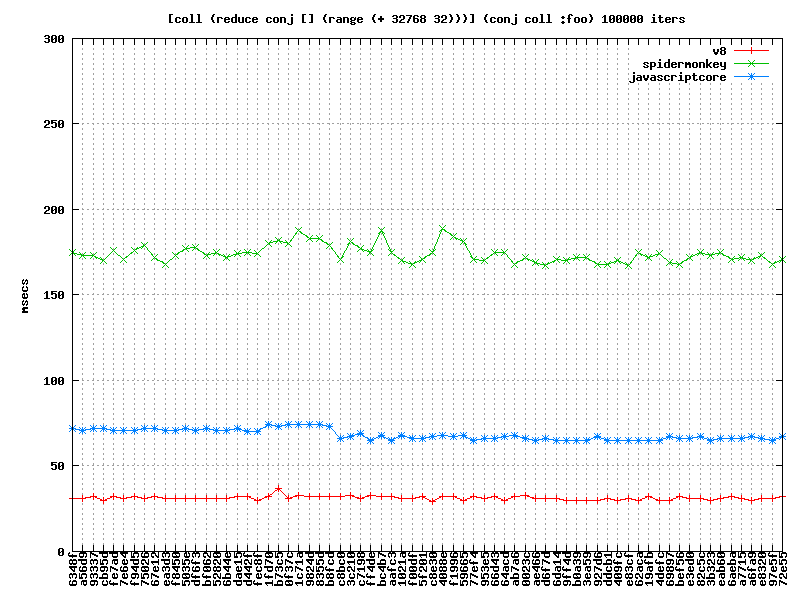
About two months ago I started a project to track how the performance of Clojurescript evolved with each commit to the repository. The project produces plots that look like this:
Each line of the plot represents a different Clojurescript runtime environment. On this plot we see Spidermonkey (the javascript implementation found in Firefox), JavaScriptCore (Webkit), and V8 (Chrome.) Also, included for comparison, is the same test running in Clojure on the JVM. I’ve carefully selected one of the cases where Clojurescript actually perfoms better than Clojure.
One of my favorite engineering professors in undergrad told me that “measurement precedes control.” This is just as true when optimizing software as it is when building actuator control systems.
Fast - FPSet can compute an intersection in O( min(n) * m ) time. In space, the algorithm is O(m). m is the number of sets. n is the number of elements in each set.
Persistent - Each set can be larger than available memory because the intersection happens while data is streamed from the disk. FPSet does not need to have the sets entirely in memory to perform the intersection.
These plots show the runtime of FPSet (blue) compared with the runtime of Ruby’s Array intersect (red) as a function of the size of the set being intersected. Check the alt-text of the image for more details.
How it works
FPSet takes any Ruby enumerable, serializes each member, sorts it, de-duplicates it, compresses it, and then writes it to a file. Creating a new set isn’t quick. FPSet is intended for applications that need very fast intersections of large sets but don’t expect to change those sets very often.
When you ask FPSet to compute the set intersection of several files it opens all of those files and decompresses just enough of the first file to find the first element in that set. It doesn’t bother to deserialize that element. Instead, at the byte level, FPSet compares that element with the first element of the next set (again, decompressing just-enough.) If the element in the second set is less than the element being searched for then that lower element cannot be in the intersection. It is discarded and the next element is read. This continues until FPSet finds a match or an element that is greater than the element being searched for. If FPSet finds a match then it compares with the third set and so on. If FPSet instead finds a greater element then the element that was being searched for cannot be in the intersection. However, the greater element may be the next member of the intersection so FPSet makes that the new searched-for element and continues streaming elements from the first set looking for a value that is equal to or greater than this new searched-for element.
If we exhaust all of the elements in one set at any point during the algorithm we know that we’ve found the complete intersection. This is where the min(n) comes from in our time complexity.
Why C?
The core algorithm of FPSet is actually implemented in ANSI C. There are two good reasons for doing this. First, the byte level comparisons that are behind the sort and intersect steps of the algorithm can be very clearly and efficiently represented in C. Second, and most important for performance, the intersection algorithm in C is expressed in a way that doesn’t allocate or free memory (no GC churn!) I’m not sure how/if one can write a Ruby equivalent of this algorithm that doesn’t keep the garbage collector busy.
Compression
Using compression when reading and writing was an interesting optimization. By far, the most expensive part of this algorithm is reading data from the disk. FPSet is completely IO bound. Modern processors are incredibly fast relative to modern disks (even SSDs.) My first implementation of FPSet wrote exactly the bytes that the algorithm would later read and compare. I discovered that the intersection was significantly faster if I added a decompression step and thus have fewer bytes to read. In my benchmarks, the runtime of FPSet decreased by 30-40% when I zlib (level 2) compressed the data.
Set Contents
You can store anything in an FPSet that Ruby knows how to Marshal.dump. I don’t know if there’s any value-like thing that Ruby doesn’t know how to marshal so I think this is a pretty loose restriction. The byte representation produced by Marshal.dump tends to be sparse but the compression we use tightens it up and makes it efficient on the disk.
RubyGems
FPSet is available through RubyGems under the name rfpset. You get it in the usual way:
Setting up a batch of new servers can be tedious. Updating and maintaining those systems over their lifetimes is also tedious. Here’s some DevOps magic to relieve some of that tedium.
The end state we’re going for is a new installation of Debian Wheezy with Puppet installed and ready to maintain and update the configuration as our needs evolve.
To follow this recipe to-the-letter you will need an already existing Debian system to build the custom installation media. You will also need a web server to host some post-install scripts. I also have a Debian apt cache on my network to speed up the installation of multiple machines.
Step 1: Automate the Installation
There are a number of ways to do this in Debian and the wonderful Debian Administrator’s Handbook is where you can read about all of them. The technique I chose is called preseeding. The standard Debian installer is designed so that all of the questions it asks you can be answered in advance in a special file called the preseed file. Here’s a preseed file I put together.
d-i debian-installer/locale string en_US
d-i console-keymaps-at/keymap select us
d-i netcfg/choose_interface select auto
# Use a local mirror instead of hitting the internet.
# You should change this to an appropriate mirror for your
# setup
d-i mirror/country string manual
d-i mirror/http/hostname string my-debian-mirror.mydomain.com
d-i mirror/http/directory string /debian
d-i mirror/http/proxy string
# Set up a user for me. This password is encrypted using the following
# command line:
#
# printf "r00tme" | mkpasswd -s -m md5
#
# Since I've disabled root login, my user will be set up automatically
# with the ability to sudo.
d-i passwd/root-login boolean false
d-i passwd/user-fullname string Brian Taylor
d-i passwd/username string btaylor
d-i passwd/user-password-crypted password $1$/Gd5fGd7$QNvq.odwNPXLo/HRuzdkw.
d-i clock-setup/utc boolean true
d-i time/zone string US/Eastern
# I also run NTP on my network so I'd like the installer to sync with
# my NTP server instead of going to the internet
d-i clock-setup/ntp boolean true
d-i clock-setup/ntp-server string my-time-server.mydomain.com
# Make all of the default decisions for partitioning my one drive. You
# can configure any setup that the installer can produce here but it
# can get complicated in a hurry
d-i partman-auto/disk string /dev/sda
d-i partman-auto/method string regular
# Shut-up any warnings if there are existing LVM or RAID devices
d-i partman-lvm/device_remove_lvm boolean true
d-i partman-md/device_remove_md boolean true
# Pick the "everything in one partition" layout
d-i partman-auto/choose_recipe select atomic
# Say yes to all the standard "are you sure you want to delete your
# disk" warnings.
d-i partman-partitioning/confirm_write_new_label boolean true
d-i partman/choose_partition select finish
d-i partman/confirm boolean true
d-i partman/confirm_nooverwrite boolean true
# Make sure my local mirror will land in /etc/apt/sources.list when
# we're all done here.
d-i apt-setup/local0/repository string http://my-debian-mirror.mydomain.com/debian/ squeeze main restricted universe multiverse
# Just a basic installation. But make sure I have SSH, puppet, and curl.
tasksel tasksel/first multiselect standard
d-i pkgsel/include string openssh-server puppet curl
d-i pkgsel/upgrade select safe-upgrade
# Put GRUB on that disk as well. Install anyway even if there's already
# an MBR on the diskd-i grub-installer/only_debian boolean true
d-i grub-installer/with_other_os boolean true
# I like to opt out of this
d-i popularity-contest/participate boolean false
# Once the installation is done we'll set the system up for some firstboot
# magic.
d-i preseed/late_command string chroot /target sh -c "/usr/bin/curl -o /tmp/postinstall http://my-web-server.mydomain.com/postinstall && /bin/sh -x /tmp/postinstall"
Step 2. Automate First-Boot Tasks
The final line of our preseed file runs a script at the end of the installation process. There’s not much room here so we just tell the installer to grab another script from our web-server and run that chrooted in our newly installed system. But, we’re still running under the installer and the installer’s post-install environment is pretty limiting. So, from our second script, we set up a service that will run a third script when the computer boots into its new installation for the first time. I’ll do all my real work in the third script.
Here’s the second postinstall script (the one that the script in the installer grabs and runs.) I host it at http://my-web-server.mydomain.com/postinstall:
12345678910111213141516171819202122232425262728
#!/bin/sh# grab our firstboot script/usr/bin/curl -o /root/firstboot http://my-web-server.mydomain.com/firstboot
chmod +x /root/firstboot
# create a service that will run our firstboot scriptcat > /etc/init.d/firstboot <<EOF### BEGIN INIT INFO# Provides: firstboot# Required-Start: $networking# Required-Stop: $networking# Default-Start: 2 3 4 5# Default-Stop: 0 1 6# Short-Description: A script that runs once# Description: A script that runs once### END INIT INFOcd /root ; /usr/bin/nohup sh -x /root/firstboot &EOF# install the firstboot servicechmod +x /etc/init.d/firstboot
update-rc.d firstboot defaults
echo"finished postinst"
Step 3. Upgrade to Wheezy
What should we do with our newly installed Debian Squeeze system? Upgrade it to Wheezy, of course! In my firstboot script, I use the preseed mechanism again to answer the questions that dist-upgrade is going to ask me. I swap out my sources.list with one that points to Wheezy and we’re off.
I wait until after I’ve upgraded to Wheezy to install my Puppet configuration. There are some changes to the Debian maintainer supplied version of the configs when we go from Squeeze to Wheezy and I want to make sure that my changes win.
This is the third post install script. It’s run the first time our newly installed Debian system boots. I host this script at http://my-web-server.mydomain.com/firstboot
#!/bin/sh# This script will run the first time the system boots. Even# though we've told it to run after networking is enabled,# I've observed inconsistent behavior if we start hitting the# net immediately.## Introducing a brief sleep makes things work right all the# time.sleep 30
# install our new sourcescat > /etc/apt/sources.list <<EOFdeb http://my-debian-mirror.mydomain.com/debian wheezy mainEOF# update apt/usr/bin/apt-get update
# install our preseed so libc doesn't whinecat > /tmp/wheezy.preseed <<EOFlibc6 glibc/upgrade boolean truelibc6 glibc/restart-services stringlibc6 libraries/restart-without-asking boolean trueEOF/usr/bin/debconf-set-selections /tmp/wheezy.preseed
# do the dist-upgrade/usr/bin/apt-get -y dist-upgrade
# configure puppet to look for the puppetmaster at a specific# machine. I really don't like the default of always naming# the puppet master "puppet". This gets around that.cat > /etc/default/puppet <<EOF# Defaults for puppet - sourced by /etc/init.d/puppet# Start puppet on boot?START=yes# Startup optionsDAEMON_OPTS=""EOFcat > /etc/puppet/puppet.conf <<EOF[main]logdir=/var/log/puppetvardir=/var/lib/puppetssldir=/var/lib/puppet/sslrundir=/var/run/puppetfactpath=$vardir/lib/factertemplatedir=$confdir/templatesserver=my-puppet-master.mydomain.comEOF# Remove our firstboot service so that it won't run againupdate-rc.d firstboot remove
# Reboot into the new kernel/sbin/reboot
Now when the system comes up for the second time it will connect to the appropriate puppetmaster and we can manage it from there using Puppet manifests.
Creating the Installation Media
To start a new machine down our path-to-glory we’ll need some kind of installation media. There are instructions online for starting a preseed installation using network booting. I opted to build a CD image instead. Thankfully, the debian tool simple-cdd makes this process quite painless.
Here’s my simple-cdd config:
1234567891011121314
# simple-cdd.conf minimal configuration file# Note: this is only an example, it is recommended to only add configuration# values as you need them.# Profiles to include on the CDprofiles="default"# set default localelocale="en_US"# Mirror for security updates# Expects security updates to be in dists/DEBIAN_DIST/updatessecurity_mirror="http://security.debian.org/"
Here are the steps:
Install simple-cdd
1
sudo apt-get install simple-cdd
Place the preseed file where simple-cdd can find it
123
cd ~
mkdir profiles
cp preseed profiles/default.preseed
Run simple-cdd with the provided configuration
1
simple-cdd --conf ./simple-cdd.conf
If all goes well you will have a freshly baked ISO waiting for you in your images directory. This is a standard awesome Debian ISO that can be burned to a disk or dd’d over to a USB flash drive. This ISO is sadly not the awesome standard Debian ISO that can be burned or dd’d to a USB disk. At the moment, the image produced by simple-cdd can only be burned to a CDROM.
I’m struggling with what seems like a simple problem: keeping my views and my models synchronized with each other.
Objectives:
Make sure that data committed by a user using a view is correctly reflected into the model.
Ensure that updates to the model from a variety of sources are correctly reflected back into any views that would be impacted by those changes.
Make sure that models know nothing about the views presenting their data.
Minimize or eliminate any knowledge that views have of the models they are mirroring.
Make sure that data committed by a user using a view is correctly reflected into the model.
Rationale: Accurately capturing the user’s intent is the whole purpose of any application.
Complications: Bare data captured by the view must be validated and transformed into the richer data-space of the model. Suppose we’re editing an email address in our contact list. When the captured data (the new email address) is returned from the view we’ll need additional knowledge (perhaps the ID of the user we were editing) before we can update the model with the new data. Where should we remember what user ID we’re editing? What if we allow the user to edit multiple email addresses simultaneously?
Solutions: The need for a place to store this binding information (user X is being edited by view Y) is one of the reasons we have “C” in “MVC.” We need some third entity to mediate the relationship between the view and the model so that neither become overly specialized. In my MOVE library I’m calling this mediating entity the “interactor” instead of a controller because I’m trying to take a slightly different approach. I am trying to embody application use-cases (like “user adds contact” or “user edits contact”) in my interactor entities. An nteractor can trigger other interactors and each is responsible for presenting an appropriate sequence of views. Some of my previous posts were written because I’ve been trying to figure out how to make flow of steps used to accomplish an interactor’s task as explicit in the code as possible. In contrast, a controller typically mediates the relationship between one kind of view and one kind of data in the model (the “contact” controller.) I stole the word “interactor” and the definition I’m using from Uncle Bob.
Ensure that updates to the model from a variety of sources are correctly reflected back into any views that would be impacted by those changes.
Rationale: The data the user is seeing in the view should be correct. The model is the canonical source of truth. Again, this is really the whole point.
Complications: We need to make good decisions about what kind changes we communicate to the view. Data-binding frameworks like SproutCore really shine in 90% of the scenarios we face here but can make the final 10% a real challenge. Aggregate views like the count of the number of items in a list are a typical corner case where data binding struggles.
Solutions: The aggregate view corner case is another opportunity to think about the coupling between view and model. Where should model derived state (like the count) be kept? It would be tempting and fairly reasonable to keep track of the count in the view. It would also be tempting but ill-advised to have the view query the model for the count directly. In a task list example I’m putting together in MOVE, I receive the list-add and list-remove events in the interactor and then query the model for the new count. Then the interactor pushes the count into the view directly.
Make sure that models know nothing about the views presenting their data.
Rationale: If the application is actually doing something interesting then there should be quite a lot of code that can be developed and tested independently of the views. Strong coupling between the model and the view could limit the usefulness of the model code in circumstances that don’t require a view (like testing, report generation, experimenting at the REPL, etc.)
Complications: Since the model is the canonical state of the world it often feels natural to push changes in the model directly out to the places we know that its needed.
Solutions: This is actually pretty easy to solve. We embrace the idea that the model should tell the world when it changes but we reject the idea that the model has any knowledge of what specifically is in the world. To accomplish this we use buzzwords like “events” or “publish-subscribe.” In my experience this works pretty well. I typically use events to communicate the novelty that the changes added (like what was added, edited, or subtracted.) I don’t use events for communicating the total state of the world (the new list of all of contacts, etc.) Since events only communicate novelty, we must avoid the mistake of having entities only observe the model through events. In my experience, such a decision forces those entities into maintaining their own internal “little-models.”
Minimize or eliminate any knowledge that views have of the models they are mirroring.
Rationale: If the view is unaware of the application’s model then it is more reusable, more testable, and less sensitive to the implementation of the model.
Complications: We don’t want the view to query the model. But, we also want to avoid creating a re-implementation of the model within the view (see “little-model” commentary in the previous objective.)
Solutions: Again we need to lean on a mediating object to help reduce the coupling between the view and the model. The strategy that is working well for me in MOVE is having the interactor register for any view-relevant change events when it creates the view. When those events fire, it is the interactor that pushes updated information to the view (perhaps after consulting the model) when it is needed. Obviously this helps make the views and models easier to test. Less intuitively, it also simplified the testing of the interactors. One approach I take is mocking the view and then firing data change events at the interactor to make sure the view is getting appropriate updates in response.
And, here’s how you use it. In this example, I’m extending
goog.ui.tree.TreeControl so that I can override handleKeyEvent and
provide a bit richer interaction with my tree.
12345678910111213141516
(nsmove.views(:require[goog.ui.tree.TreeControl:asTreeControl])(:use-macros[move.macros:only[goog-extend]][cljs.core:only[this-as]]))(goog-extendMyTreegoog/ui.tree.TreeControl([nameconfig](this-asthis(goog/basethisnameconfig)))(handleKeyEvent[e](this-asthis(goog/basethis"handleKeyEvent"e);; my special code to handle the key event)))
When this is compiled, it expands to this javascript:
123456789101112
move.views.MyTree=functionMyTree(name,config){varthis__44428=this;returngoog.base(this__44428,name,config)};goog.inherits(move.views.MyTree,goog.ui.tree.TreeControl);move.views.MyTree.prototype.handleKeyEvent=function(e){varthis__44429=this;goog.base(this__44429,"handleKeyEvent",e);// my special code to handle the key event};
Cool! That’s pretty close to the code I need to write by hand when
extending google closure classes in my javascript code.
This code will work great if we compile with standard optimizations
but we get into trouble in advanced mode. The Closure compiler does
more error checking in advanced mode and wrongly flags our call to
goog.base for not having this as its first argument. That’s
unfortunate but not a big deal. We just have to write some less
idiomatic code to fix it:
1234567891011121314
(nsmove.views(:require[goog.ui.tree.TreeControl:asTreeControl])(:use-macros[move.macros:only[goog-extend]][cljs.core:only[this-as]]))(goog-extendMyTreegoog/ui.tree.TreeControl([nameconfig](goog/base(js*"this")nameconfig))(handleKeyEvent[e](goog/base(js*"this")"handleKeyEvent"e);; my special code to handle the key event)))
This will generate the code that the advanced compiler is looking for.
Christopher’s comments to
yesterday’s post
forced me to think more about the return value of the doasync form and
whether it would make sense to give it a body.
doasync doesn’t return anything useful. How could it? doasync is
designed for callback driven code that’s probably ultimately pumped by
the event loop. So, when it is time to return from the form we
probably haven’t actually done anything yet.
But, as I was using doasync to write
interactors,
I noticed that all of my doasync forms really did have a “return”
value that they were passing on to their own callback (nextfn in the
linked code.) This sounds like a pattern to capture in a new macro.
defasync
works like a defn but for defining asynchronous functions. I define an
“asynchronous function” to be a function that takes a callback as its
last argument and “returns” its ultimate value by passing it to the
callback exactly once. Since my definition includes a “return” value
we finally have a reasonable place to put whatever the body computes.
Here’s how my asynchronous function definitions looked before:
123456
(defn get-current-list[statenextfn]"[async] get the current list from the server and update the model"(doasync[current-list[get-json"/resources/current-list.json"]_(models/set-current-liststatecurrent-list)_(nextfncurrent-list)]))
And here’s how they look now:
123456
(defasyncget-current-list[state]"[async] get the current list from the server and update the model"[current-list[get-json"/resources/current-list.json"]](models/set-current-liststatecurrent-list)current-list)
I’m trying to mimic defn as much as possible with defasync. Like defn,
defasync has a name and a set of arguments. After an optional docstring,
defasync accepts a vector containing the same asynchronous sequential
binding style as doasync. This is the only part of the code where the
asynchronous invocation form [func arg1 arg2] is allowed.
Next comes the body. The body is executed once all of the bindings are
established. The return value of the body is passed to our now
implicit nextfn. Did you notice that nextfn is missing? It’s inserted
into the last slot in the argument list by defasync and only invoked
once with the result of executing the body.
Here’s another example (again from
interactors.)
Here we create a dialog asking the user for input and then collect the
result when it becomes available. In the body we update our model with
the user’s new data.
1234567
(defasynccreate-new-todo[stateview]"[async] create a new item in the current list"[list(models/current-liststate)input-dialog(views/make-input-dialog"What do you want to do?")input[events/register-once[:ok-clickedinput-dialog]]](models/add-todostatelistinput))
 vs number of elements. 1 set intersection")
 vs number of elements. 2 set intersection")
 vs number of elements. 3 set intersection")
 vs number of elements. 5 set intersection")
 vs number of elements. 6 set intersection")
 vs number of elements. 7 set intersection")